KoBERT 감정분석 다이어리
데이터 청년 캠퍼스: 황수민, 김유화, 김민수, 두소원, 추다연, 박상희
프로젝트 개발 배경
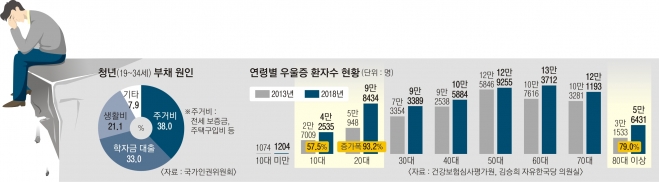
올 상반기 정신질환자 증가율이 전년대비 40%나 급증했다. 신종 코로나바이러스 감염증(코로나19) 장기화 등으로 코로나19 우울(블루)이 통계로 확인됐다는 분석이다. 그 중에 청년층 정신질환 환자가 특히 증가했다. 최근 5년간 공황장애, 불안장애, 우울증, 조울증으로 진료 받은 환자 가운데 각 질환별 증가율 1위는 모두 20대였다. 실제, 지난해 전체 진료환자 중 20대(중복건수포함)는 20만 5847명으로 2014년 10만 7982명에서 5년새 90.6%가 증가해 가장 높은 증가율을 보였으며, 이어 10대(66%), 30대(39.9%) 순으로 나타났다. 정신질환은 자해로 이어지기도 한다. 2020년 상반기 청년층의 자해 발생 진료 건수가 지난해 같은 기간에 견줘 두배 가까이 늘어났다.
코로나 시대를 살아가는 현대인은 정신질환을 많이 가지고 있다. 특히 청년층이 심각한 것으로 보인다.
일기 치료는 실제로 환자의 정신질환에 있어 효과가 있고 환자를 상태를 알기 위해 쓰이기도 한다. 우울증 초기에도 효과적으로 사용되는 방법 중 하나이다.
따라서 본 프로젝트는 정신건강의학과에서 환자를 대상으로 한 신조어 감성분석을 이용한 개인 감정 진단 시스템을 구현하는 것이 프로젝트의 목표로 한다. 웹이나 앱으로 만들어진 감성 일기는 보통 젊은 세대가 많이 사용하기 때문에 감정분석의 정확도를 높히기 위해 신조어 분석 또한 실행한다.
일기장에 일기를 입력했을 때 행복, 즐거움, 분노, 슬픔 4가지 감정을 분류하여 감정을 시각화 하여 나타낸다.
KoBERT Model
 한국어 문장을 여러 감정으로 분류하는 다중 분류 모델을 만들기 위하여 KoBERT를 사용하였다. KoBERT는 기존의 BERT의 한국어 성능 한계로 인해 만들어졌다. 한국어 위키의 문장과 단어들을 추가하여 학습시킨 모델이다.
한국어 문장을 여러 감정으로 분류하는 다중 분류 모델을 만들기 위하여 KoBERT를 사용하였다. KoBERT는 기존의 BERT의 한국어 성능 한계로 인해 만들어졌다. 한국어 위키의 문장과 단어들을 추가하여 학습시킨 모델이다.
구현 과정

데이터 수집
데이터 크롤링: 트위터에서 진행하도록 함. 문장을 작성할 때 글자 제한수가 있어 문장길이가 상대적으로 길지 않고, 신조어를 자주 사용하기 때문에 적합하다고 판단했다.

import tweepy
import pandas as pd
tweets_df =[]
consumer_key = " "
consumer_secret = " "
access_token = " "
access_token_secret = " "
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth,wait_on_rate_limit=True)
text_query = '키워드 -RT'
count = 1000
try:
# Creation of query method using parameters
tweets = tweepy.Cursor(api.search,q=text_query).items(count)
# Pulling information from tweets iterable object
tweets_list = [[tweet.created_at, tweet.id, tweet.text] for tweet in tweets]
# Creation of dataframe from tweets list
# Add or remove columns as you remove tweet information
tweets_df = pd.DataFrame(tweets_list, columns= ['a', 'b', 'raw_text'])
except BaseException as e:
print('failed on_status,',str(e))
del tweets_df['a']
del tweets_df['b']
- 트위터 클롤링 시에 사용된 라이브러리는 tweepy이다. 현재 트위터에서 허용되지 않은 다른 모든 라이브러리는 막혀있기 때문에 개발자 등록이 필수이다.
import re
new_commnets=[]
for i in range(len(tweets_df)):
d=re.sub(r'[0-9]+', '', tweets_df['raw_text'][i])
d= re.sub(r'(https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*))'
, '', d) #url 지우기
d= re.sub(r'@[0-9a-zA-Z가-힣ㄱ-ㅎ-_]+', '', d) #멘션 아이디 지우기
new_commnets.append(d)
df = pd.DataFrame(new_commnets, columns=['raw_text'])
df
df.to_excel('Happy2.xlsx') #기쁨 저장
-
크롤링한 데이터들 중 url과 멘션 아이디를 삭제하는 전처리를 수행한다.
-
전처리된 문장들을 xlsx 파일 형태로 저장한다.
행복:5,567, 즐거움: 5,507, 슬픔 : 5,776개, 분노: 4,867
데이터 전처리
# 전처리 함수
def preprocessing(data, label):
import re
dt = data['raw_text'].copy()
dt = dt.dropna()
dt = dt.drop_duplicates()
sentences = dt.tolist()
new_sent=[]
for i in range(len(sentences)):
sent = sentences[i]
if type(sent) != str:
sent = str(sent)
if len(sent) < 2: continue
sent = re.sub('\n',' ',sent)
sent = re.sub('ㅋㅋ+','ㅋㅋ',sent)
sent = re.sub('ㅠㅠ+','ㅠㅠ',sent)
sent = re.sub('ㅇㅇ+','ㅇㅇ',sent)
sent = re.sub('ㄷㄷ+','ㄷㄷ',sent)
sent = re.sub('ㅎㅎ+','ㅎㅎ',sent)
sent = re.sub('ㅂㅂ+','ㅂㅂ',sent)
sent = re.sub(';;;+',';;',sent)
sent = re.sub('!!!+','!!',sent)
sent = re.sub('~+','~',sent)
sent = re.sub('[?][?][?]+','??',sent)
sent = re.sub('[.][.][.]+','...',sent)
sent = re.sub('[-=+,#/:$@*\"※&%ㆍ』\\‘|\(\)\[\]\<\>`\'…》]','',sent)
new_sent.append(sent)
dt = pd.DataFrame(pd.Series(new_sent), columns=['raw_text'])
dt['emotion'] = label
return dt
- 트위터에서 크롤링된 텍스트에서 반복되는 자음들을 제거하는 전처리를 수행한다.
- emotion 칼럼에 해당하는 감정 label을 붙인다.
KoBERT 모델 학습
환경 세팅 KoBERT 환경에서 사용되는 mxnet, gluonnlp, torch, kobert를 사용하게 위해서는 우선적으로 CUDA 환경을 세팅해줄 필요가 있다. 자세한 사항은 여기에서 확인할 수 있다.
이번 프로젝트에서는 CUDA 10.1 버전을 기준으로 진행하였다.
def label(x):
if x=='행복': return 0.0
elif x=='즐거움': return 1.0
elif x=='슬픔': return 2.0
elif x=='분노': return 3.0
else: return x
sentence_train["emotion"] = sentence_train["emotion"].apply(label)
- 네가지 감정에 따라 레이블링을 처리하는 함수를 만든다.
pip install mxnet-cu101
pip install gluonnlp pandas tqdm
pip install sentencepiece==0.1.85
pip install transformers==2.1.1
pip install torch
#SKT에서 공개한 KoBERT 모델을 불러오기
!pip install git+https://git@github.com/SKTBrain/KoBERT.git@master
- 기본 모델을 만들 떄 사용되는 라이브러리들을 import한다. 이때 mxnet은 CUDA의 버전에 따라 다른 숫자를 사용해야 한다.
- 현재 이 프로젝트에서 사용되는 CUDA는 10.1버전 기준이기 때문에 mxnet-cu101을 사용한다.
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
from tqdm.notebook import tqdm
from kobert.utils import get_tokenizer
from kobert.pytorch_kobert import get_pytorch_kobert_model
from transformers import AdamW
from transformers.optimization import WarmupLinearSchedule
- 위에서 정상적으로 모델이 임포트 되어있을 경우 문제 없이 사용된다.
device = torch.device("cuda:0")
bertmodel, vocab = get_pytorch_kobert_model()
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)
- KoBERT를 사용하는 과정에서 GPU를 이용하기 위한 사전 세팅 방법
- CUDA의 설치 버전이 일치하지 않을 경우 에러가 발생할 수 있다.
#학습 과정
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm(train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
model.eval() # 모델 평가
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
print("epoch {} test acc {}".format(e+1, test_acc / (batch_id+1)))
- 사용되는 KoBERT 모델 구현 함수는 SKT KoBERT를 참고한다.
- 새로 크롤링한 트위터 텍스트 데이터를 추가적으로 학습시킨다.
torch.save(model.state_dict(), 'drive/My Drive/data/kobert_ending_finale.pt')
- 추후에 Django에서 사용할 학습된 모델을 파일의 형태로 저장한다.
모델 테스트
def data_preprocess(data):
raw = re.split('[\r\n\.\?\!]', data)
text = []
for val in raw:
if val == '':
continue
text.append([val, 0.0])
print(text)
return text
def normalize(result):
max_ = max(result)
min_ = min(result)
list = []
for val in result:
val = (val - min_)/(max_ - min_)
list.append(round(val,2))
print(list)
return list
def predict(model, text):
device = torch.device("cuda:0")
max_len = 64
batch_size = 64
warmup_ratio = 0.1
num_epochs = 2
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-5
tokenizer = get_tokenizer()
bertmodel, vocab = get_pytorch_kobert_model()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)
data_test = BERTDataset(text, 0, 1, tok, max_len, True, False)
test_dataloader = torch.utils.data.DataLoader(data_test, batch_size=batch_size, num_workers=0)
model.eval()
answer=[]
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
max_vals, max_indices = torch.max(out, 1)
answer.append(max_indices.cpu().clone().numpy())
result = F.softmax(out)
print(result)
return result
def calc_result(result):
sadness = 0.0
joy = 0.0
anger = 0.0
happy = 0.0
result = result.detach().cpu().clone().numpy()
for data in result:
sadness += data[0]
joy += data[1]
anger += data[2]
happy += data[3]
result = [sadness, joy, anger, happy]
results = normalize(result)
results = [0.1 if x == 0.0 else x for x in results]
results = {'sadness': results[0], 'joy': results[1], 'anger': results[2], 'happy': results[3]}
return results
text = data_preprocess('오늘은 정말로 행복한 날이었다. 간식이 짱 맛나서 정말 좋았다. 그런데 적어서 좀 슬펐다. 잉이이이이잉...')
file='/content/drive/My Drive/data/kobert_ending_finale.pt'
device = torch.device("cuda:0")
bertmodel, vocab = get_pytorch_kobert_model()
model = BERTClassifier(bertmodel, dr_rate=0.5).to(device)
model.load_state_dict(torch.load(file))
model.eval()
result = predict(model, text)
results = calc_result(result)
print(results)
- 학습한 모델이 잘 동작하는지 간단하게 테스트를 진행해본다.
웹사이트 구현
Django
주의: 디렉토리 파일명에 한글이 들어있지 않도록 주의 -> 에러 발생 가능성 있음
필요한 모듈 설치
- pip install django-sslserver
-
KoBERT
git clone https://github.com/SKTBrain/KoBERT.git cd KoBERT pip install -r requirements.txt pip install . #kobert 설치법 - pip3 install adaptnlp
- pip install mxnet-cu101
- pip install gluonnlp pandas tqdm
- pip install sentencepiece==0.1.85
- pip install transformers==2.1.1
- pip install torch
- 장고 설치
pip install django- cmd에서 먼저 장고를 설치한다.
- vscode에서 코딩 진행
- 장고 return 디렉토리 생성
django-admin startproject return- 파일 명은 필요에 맞게 수정한다.
- diary 디렉토리 생성
python manage.py startapp diary -
views.py에 모델 함수 추가
import os import re from django.shortcuts import render, redirect from django.http import HttpResponse, JsonResponse from .models import User, Result, Content from .forms import ContentForm, UserForm, ResultForm import os import re import torch from torch import nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import Dataset, DataLoader import gluonnlp as nlp import numpy as np from tqdm import tqdm, tqdm_notebook from tqdm.notebook import tqdm from kobert.utils import get_tokenizer from kobert.pytorch_kobert import get_pytorch_kobert_model from transformers import AdamW from transformers import WarmupLinearSchedule as get_linear_schedule_with_warmup from sklearn.model_selection import train_test_split from django.views.decorators.csrf import csrf_exempt # Create your views here. module_dir = os.path.dirname(__file__) max_len = 64 batch_size = 64 warmup_ratio = 0.1 num_epochs = 1 max_grad_norm = 1 log_interval = 200 learning_rate = 5e-5 class BERTDataset(Dataset): def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer, max_len, pad, pair): transform = nlp.data.BERTSentenceTransform( bert_tokenizer, max_seq_length=max_len, pad=pad, pair=pair) self.sentences = [transform([i[sent_idx]]) for i in dataset] self.labels = [np.int32(i[label_idx]) for i in dataset] def __getitem__(self, i): return (self.sentences[i] + (self.labels[i], )) def __len__(self): return (len(self.labels)) class BERTClassifier(nn.Module): def __init__(self, bert, hidden_size = 768, num_classes=4, dr_rate=None, params=None): super(BERTClassifier, self).__init__() self.bert = bert self.dr_rate = dr_rate self.classifier = nn.Linear(hidden_size , num_classes) if dr_rate: self.dropout = nn.Dropout(p=dr_rate) def gen_attention_mask(self, token_ids, valid_length): attention_mask = torch.zeros_like(token_ids) for i, v in enumerate(valid_length): attention_mask[i][:v] = 1 return attention_mask.float() def forward(self, token_ids, valid_length, segment_ids): attention_mask = self.gen_attention_mask(token_ids, valid_length) _, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device)) if self.dr_rate: out = self.dropout(pooler) return self.classifier(out) def index(request): return render(request, 'diary/diary.html') def analysis(request): if request.method == 'POST': data = request.read().decode('utf-8') text = data_preprocess(data) print(data) file ='C:/Users/kie69/Desktop/project2/return/diary/kobert_ending_finale.pt' device = torch.device("cuda:0") bertmodel, vocab = get_pytorch_kobert_model() model = BERTClassifier(bertmodel, dr_rate=0.5).to(device) model.load_state_dict(torch.load(file)) model.eval() result = predict(model, text) results = calc_result(result) print(results) return JsonResponse({"results":results}) def result(request): if request.method == 'POST': form = ContentForm(request.POST) data = form.data['text'] return render(request, 'diary/result.html', {'text':data}) def data_preprocess(data): raw = re.split('[\r\n\.\?\!]', data) #raw = data.replace('\r\n', ' ').replace('.', ' ').replace('\?', ' ') text = [] for val in raw: if val == '': continue text.append([val, 0.0]) print(text) return text def predict(model, text): device = torch.device("cuda:0") max_len = 64 batch_size = 64 warmup_ratio = 0.1 num_epochs = 2 max_grad_norm = 1 log_interval = 200 learning_rate = 5e-5 tokenizer = get_tokenizer() bertmodel, vocab = get_pytorch_kobert_model() tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False) data_test = BERTDataset(text, 0, 1, tok, max_len, True, False) test_dataloader = torch.utils.data.DataLoader(data_test, batch_size=batch_size, num_workers=0) model.eval() answer=[] for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)): token_ids = token_ids.long().to(device) segment_ids = segment_ids.long().to(device) valid_length= valid_length label = label.long().to(device) out = model(token_ids, valid_length, segment_ids) max_vals, max_indices = torch.max(out, 1) answer.append(max_indices.cpu().clone().numpy()) result = F.softmax(out) print(result) return result def calc_result(result): happy = 0.0 joy = 0.0 sadness = 0.0 angry = 0.0 result = result.detach().cpu().clone().numpy() for data in result: happy += data[0] joy += data[1] sadness += data[2] angry += data[3] print(result) result = [happy, joy, sadness, angry] results = normalize(result) results = [0.1 if x == 0.0 else x for x in results] results = {'happy': results[0], 'joy': results[1], 'sadness': results[2], 'angry': results[3]} return results def normalize(result): max_ = max(result) min_ = min(result) list = [] for val in result: val = (val - min_)/(max_ - min_) list.append(round(val,2)) print(list) return list- analysis 함수에서 이전에 저장해둔 학습된 모델을 불러와 사용한다.
- 계산된 데이터를 바깥으로 불러낼 때, 학습시킨 모델의 감정 라벨링 순서대로 불러내어야 한다.
- 계산된 결과는 result에 저장되어 post 된다.
- templates/diary의 html과 연결
- diary.html과 result.html은 index.html에서 extends를 통해 나타난다.
- 일기의 텍스트 내용은 diary.html에서 입력되며, 결과의 출력은 result.html에서 나타난다.
-
장고 실행
python manage.py makemigrations diary #다이어리 마이그래이션 만들기 python manage.py migrate python manage.py runserver #서버 실행
이슈사항
-
CUDA 사용 불가 문제
- 일반적으로 CUDA 버전 문제로 인해 발생한다. CUDA 설치 버전과 맞는 cuDNN과 pytorch가 설치되어있는지 확인해본다.
- 컴퓨터의 GPU 사양이 너무 낮을 경우 제대로 동작하지 않을 수도 있다.
- sslserver not found 문제
- sslserver은 pip install django-sslserver를 통해 설치해야 한다.
- 디렉토리 이슈
- 설치된 KoBERT의 라이브러리를 불러오는 도중, 경로에 한글이 포함되어있을 경우, 에러가 발생한다. 따라서 경로에 한글이 포함되징 않도록 주의한다.
- from transformers import WarmupLinearSchedule 사용 불가 이슈
- 임포트된 모듈 중 버전 문제로 인해 사용되지 않는 것으로 파악된다. 따라서 위와 같은 에러가 발생할 시,
from transformers import WarmupLinearSchedule as get_linear_schedule_with_warmup로 변경하여 사용하도록 한다.
- 임포트된 모듈 중 버전 문제로 인해 사용되지 않는 것으로 파악된다. 따라서 위와 같은 에러가 발생할 시,